Spark Streaming in Details¶
Feng Li¶
Central University of Finance and Economics¶
feng.li@cufe.edu.cn¶
Course home page: https://feng.li/distcomp¶
Transformations on DStreams¶
Similar to that of RDDs, transformations allow the data from the input DStream to be modified. DStreams support many of the transformations available on normal Spark RDD’s. Some of the common ones are as follows.
| transformation | Meaning |
|---|---|
| map(func) | Return a new DStream by passing each element of the source DStream through a function func. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items. |
| filter(func) | Return a new DStream by selecting only the records of the source DStream on which func returns true. |
| repartition(numPartitions) | Changes the level of parallelism in this DStream by creating more or fewer partitions. |
| union(otherStream) | Return a new DStream that contains the union of the elements in the source DStream and otherDStream. |
| count() | Return a new DStream of single-element RDDs by counting the number of elements in each RDD of the source DStream. |
| reduce(func) | Return a new DStream of single-element RDDs by aggregating the elements in each RDD of the source DStream using a function func (which takes two arguments and returns one). The function should be associative and commutative so that it can be computed in parallel. |
| countByValue() | When called on a DStream of elements of type K, return a new DStream of (K, Long) pairs where the value of each key is its frequency in each RDD of the source DStream. |
| reduceByKey(func, [numTasks]) | When called on a DStream of (K, V) pairs, return a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function. Note: By default, this uses Spark's default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config property spark.default.parallelism) to do the grouping. You can pass an optional numTasks argument to set a different number of tasks. |
| join(otherStream, [numTasks]) | When called on two DStreams of (K, V) and (K, W) pairs, return a new DStream of (K, (V, W)) pairs with all pairs of elements for each key. |
| cogroup(otherStream, [numTasks]) | When called on a DStream of (K, V) and (K, W) pairs, return a new DStream of (K, Seq[V], Seq[W]) tuples. |
| transform(func) | Return a new DStream by applying a RDD-to-RDD function to every RDD of the source DStream. This can be used to do arbitrary RDD operations on the DStream. |
| updateStateByKey(func) | Return a new "state" DStream where the state for each key is updated by applying the given function on the previous state of the key and the new values for the key. This can be used to maintain arbitrary state data for each key. |
Window Operations¶
Spark Streaming also provides windowed computations, which allow you to apply transformations over a sliding window of data.
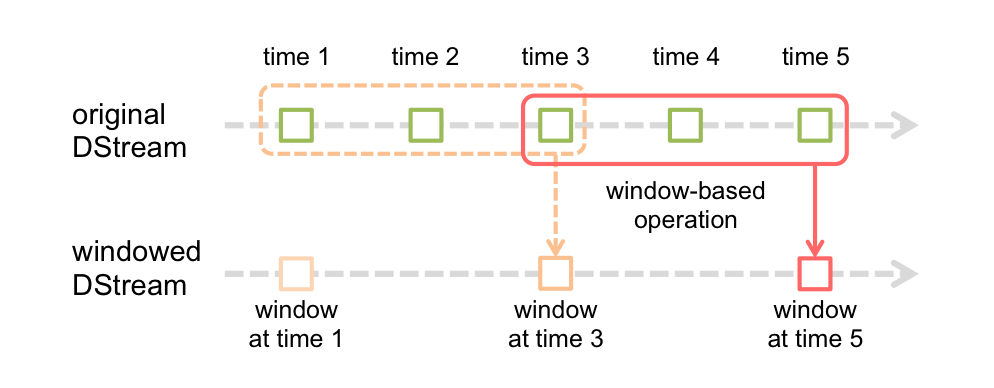
Any window operation needs to specify two parameters.
- window length - The duration of the window (3 in the figure).
- sliding interval - The interval at which the window operation is performed (2 in the figure).
These two parameters must be multiples of the batch interval of the source DStream (1 in the figure).
Output Operations on DStreams¶
Output operations allow DStream’s data to be pushed out to external systems like a database or a file systems.
Since the output operations actually allow the transformed data to be consumed by external systems, they trigger the actual execution of all the DStream transformations (similar to actions for RDDs). Currently, the following output operations are defined:
| Output Operation | Defination |
|---|---|
print() |
Prints the first ten elements of every batch of data in a DStream on the driver node running the streaming application. This is useful for development and debugging.This is called pprint() in the Python API. |
saveAsTextFiles() |
Save this DStream's contents as text files. |
saveAsObjectFiles() |
Save this DStream's contents as SequenceFiles of serialized Java objects. This is not available in the Python API. |
saveAsHadoopFiles() |
Save this DStream's contents as Hadoop files. This is not available in the Python API. |
foreachRDD(func) |
The most generic output operator that applies a function, func, to each RDD generated from the stream. This function should push the data in each RDD to an external system, such as saving the RDD to files, or writing it over the network to a database. Note that the function func is executed in the driver process running the streaming application, and will usually have RDD actions in it that will force the computation of the streaming RDDs. |
External Data Sources¶
As of Spark 2.4.5, Kafka, Kinesis and Flume are available in the Python API.
This category of sources require interfacing with external non-Spark libraries, some of them with complex dependencies (e.g., Kafka and Flume). Hence, to minimize issues related to version conflicts of dependencies, the functionality to create DStreams from these sources has been moved to separate libraries that can be linked to explicitly when necessary.
Note that these advanced sources are not available in the Spark shell, hence applications based on these advanced sources cannot be tested in the shell. If you really want to use them in the Spark shell you will have to download the corresponding Maven artifact’s JAR along with its dependencies and add it to the classpath.
Some of these advanced sources are as follows.
Kafka: Spark Streaming 2.4.5 is compatible with Kafka broker versions 0.8.2.1 or higher. See the Kafka Integration Guide for more details.
Flume: Spark Streaming 2.4.5 is compatible with Flume 1.6.0. See the Flume Integration Guide for more details.
Kinesis: Spark Streaming 2.4.5 is compatible with Kinesis Client Library 1.2.1. See the Kinesis Integration Guide for more details.