Introduction to Spark Streaming¶
Feng Li¶
Central University of Finance and Economics¶
feng.li@cufe.edu.cn¶
Course home page: https://feng.li/distcomp¶
Overview of Spark Streaming¶
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams.
Data can be ingested from many sources like Kafka, Flume, Kinesis, or TCP sockets, and can be processed using complex algorithms expressed with high-level functions like
map,reduce,joinandwindow.You can apply Spark’s machine learning and graph processing algorithms on data streams.
Processed data can be pushed out to filesystems, databases, and live dashboards.

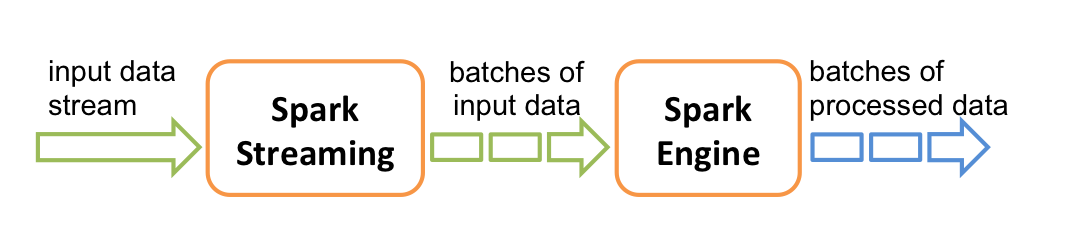
Work Flow of Streaming Data Modelling¶
Spark Streaming receives live input data streams
Spark Streaming divides the data into batches.
The streaming data are then processed by the Spark engine to generate the final stream of results in batches.
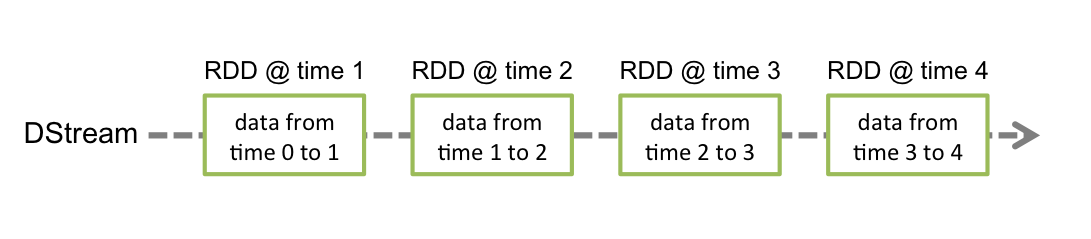
DStream -- Spark's representation of streaming of data¶
Spark Streaming provides a high-level abstraction called
discretized streamorDStream, which represents a continuous stream of data.DStreams can be created either from input data streams from sources such as Kafka, Flume, and Kinesis, or by applying high-level operations on other DStreams.
Internally, a DStream is represented as a sequence of RDDs.
import findspark ## Only needed when you run spark witin Jupyter notebook
findspark.init()
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder\
.config("spark.executor.memory", "2g")\
.config("spark.cores.max", "2")\
.master("spark://master:7077")\
.appName("Python Spark").getOrCreate() # using spark server
First, we import
StreamingContext, which is the main entry point for all streaming functionality.We create a local StreamingContext, and batch interval of 10 seconds.
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# Create a local StreamingContext with two working thread and batch interval of 1 second
sc = spark.sparkContext # make a spark context for RDD
ssc = StreamingContext(sc, 10) # batch interval of 10 seconds.
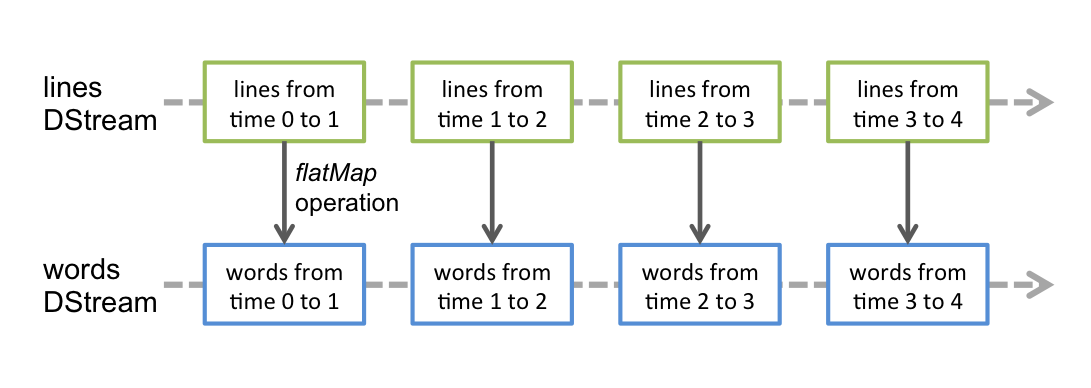
We create a DStream that represents streaming data from a TCP source, specified as hostname (e.g. localhost) and port (e.g. 9999).
lines = ssc.socketTextStream("localhost", 9999)
words = lines.flatMap(lambda line: line.split(" "))
This
linesDStream represents the stream of data that will be received from the data server. Each record in this DStream is a line of text. Next, we want to split the lines by space into words.flatMapis a one-to-many DStream operation that creates a new DStream by generating multiple new records from each record in the source DStream. In this case, each line will be split into multiple words and the stream of words is represented as the words DStream. Next, we want to count these words.
# Count each word in each batch
pairs = words.map(lambda word: (word, 1))
wordCounts = pairs.reduceByKey(lambda x, y: x + y)
# Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.pprint()
The
wordsDStream is further mapped (one-to-one transformation) to a DStream of (word, 1) pairs, which is then reduced to get the frequency of words in each batch of data.Finally,
wordCounts.pprint()will print a few of the counts generated every second.
Spark Streaming only sets up the computation it will perform when it is started, and no real processing has started yet. To start the processing after all the transformations have been setup, we finally call
ssc.start() # Start the computation
ssc.awaitTermination() # Wait for the computation to terminate
You will first need to run Netcat (a small utility found in most Unix-like systems) as a data server by using
nc -lk 9999
Then, any lines typed in the terminal running the netcat server will be counted and printed on screen every second. It will look something like the following.
ssc.stop()
Summary¶
Define the input sources by creating input DStreams.
Define the streaming computations by applying transformation and output operations to DStreams.
Start receiving data and processing it using
streamingContext.start().Wait for the processing to be stopped (manually or due to any error) using streamingContext.awaitTermination().
The processing can be manually stopped using
streamingContext.stop().
Points to remember:¶
Once a context has been started, no new streaming computations can be set up or added to it.
Once a context has been stopped, it cannot be restarted.
Only one StreamingContext can be active in a JVM at the same time.
stop()on StreamingContext also stops the SparkContext. To stop only the StreamingContext, set the optional parameter ofstop()called stopSparkContext to false.A SparkContext can be re-used to create multiple StreamingContexts, as long as the previous StreamingContext is stopped (without stopping the SparkContext) before the next StreamingContext is created.
Wordcount from HDFS files¶
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
sc = SparkContext(appName="PythonStreamingHDFSWordCount")
ssc = StreamingContext(sc, 10)
lines = ssc.textFileStream(sys.argv[1])
counts = lines.flatMap(lambda line: line.split(" "))\
.map(lambda x: (x, 1))\
.reduceByKey(lambda a, b: a+b)
counts.pprint()
ssc.start()
ssc.awaitTermination()