Introduction to Spark¶
Feng Li¶
Central University of Finance and Economics¶
feng.li@cufe.edu.cn¶
Course home page: https://feng.li/distcomp¶
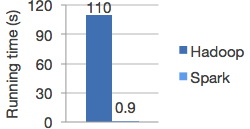
Who created Spark¶
Spark was a PhD student project in Berkerley University.
Matei Zaharia was the major contributor during his PhD at UC Berkeley in 2009.
Matei’s research work was recognized through the 2014 ACM Doctoral Dissertation Award for the best PhD dissertation in computer science, an NSF CAREER Award, and the US Presidential Early Career Award for Scientists and Engineers (PECASE).
Ease of Use¶
Write applications quickly in Java, Scala, Python, R, and SQL.
Spark offers over 80 high-level operators that make it easy to build parallel apps. And you can use it interactively from the Scala, Python, R, and SQL shells.
DataFrame with pandas API support
Generality¶
Combine SQL, streaming, and complex analytics.
Spark powers a stack of libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application.
Runs Everywhere¶
Spark runs on Hadoop, Apache Mesos, Kubernetes, standalone, or in the cloud. It can access diverse data sources.
You can run Spark using its standalone cluster mode, on EC2, on Hadoop YARN, on Mesos, or on Kubernetes. Access data in HDFS, Alluxio, Apache Cassandra, Apache HBase, Apache Hive, and hundreds of other data sources.

Spark architecture¶
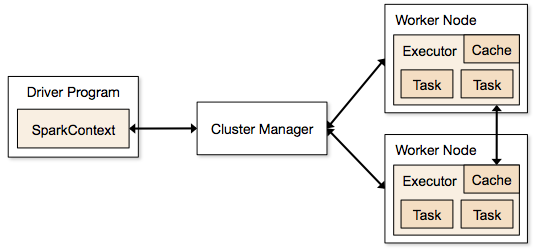
Spark Built-in Libraries:¶
- SQL and DataFrames
- Spark Streaming
- MLlib, ML (machine learning)
- GraphX (graph)
Launching Applications with spark-submit¶
Once a user application is bundled, it can be launched using the bin/spark-submit script. This script takes care of setting up the classpath with Spark and its dependencies, and can support different cluster managers and deploy modes that Spark supports:
spark-submit \ --class <main-class> \ --master <master-url> \ --deploy-mode <deploy-mode> \ --conf <key>=<value> \ ... # other options <application> \ [application-arguments]
Run on a YARN cluster¶
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \ # can be client for client mode
--executor-memory 20G \
--num-executors 50 \
/path/to/examples.jar \
1000
Run a Python application on a Spark-on-YARN cluster¶
PYSPARK_PYTHON=python3.7 spark-submit \
--master yarn \
examples/src/main/python/pi.py \
1000
Spark with R¶
Spark also provides an experimental R API since 1.4 (only DataFrames APIs included).
To run Spark interactively in a R interpreter, use
sparkR:sparkR --master local[2]Example applications are also provided in R. For example,
spark-submit examples/src/main/r/dataframe.R
Run Spark via Pyspark¶
It is also possible to launch the PySpark shell. Set
PYSPARK_PYTHONvariable to select the approperate Python when runningpysparkcommand:PYSPARK_PYTHON=python3.7 pyspark
Run spark interactively within Python¶
You could use spark as a Python's module, but
PySparkisn't onsys.pathby default.That doesn't mean it can't be used as a regular library.
You can address this by either symlinking pyspark into your site-packages, or adding pyspark to sys.path at runtime. findspark does the latter.
To initialize PySpark, just call it within Python
import findspark
findspark.init()
- Then you could import the
pysparkmodule
import pyspark