Understanding MapReduce¶
Feng Li¶
Central University of Finance and Economics¶
feng.li@cufe.edu.cn¶
Course home page: https://feng.li/distcomp¶
(Key, Value) Pairs in MapReduce¶
- When the Map/Reduce framework reads a line from the stdout of the mapper, it splits the line into a key/value pair.
- The prefix of the line up to the first tab character is the key and the rest of the line (excluding the tab character) is the value.

Shuffle and Sort¶
MapReduce makes the guarantee that the input to every reducer is sorted by key.
The process by which the system performs the sort, and transfers the map outputs to the reducers as inputs is known as the shuffle.
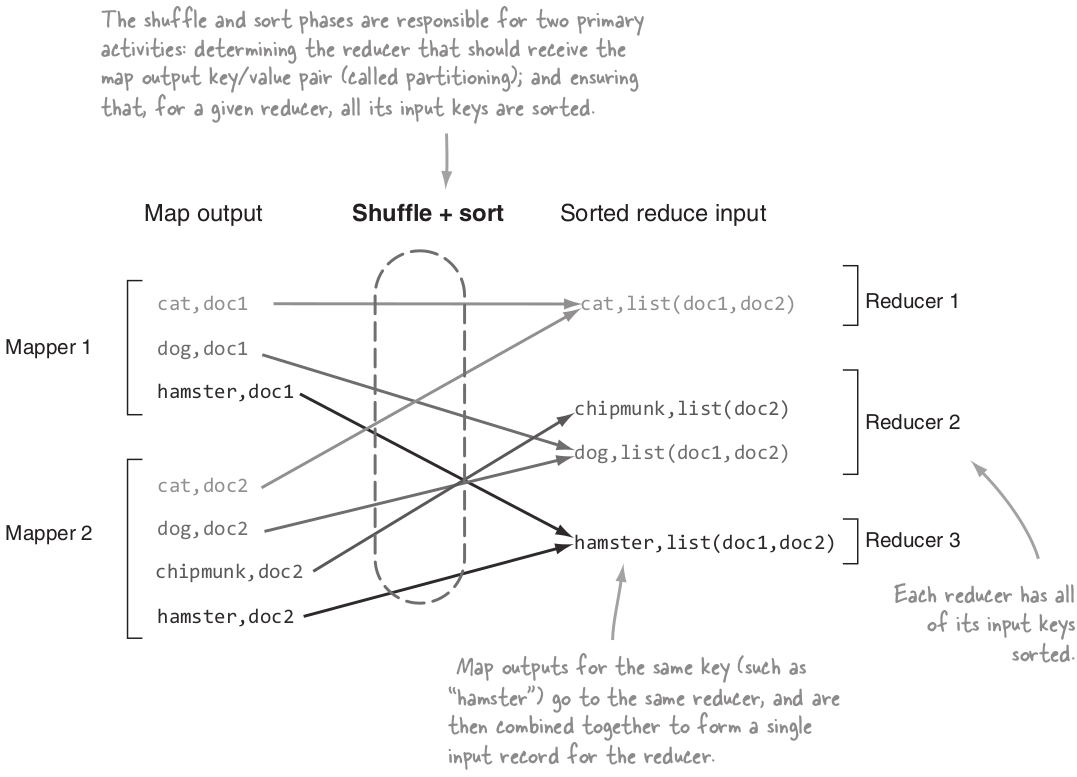
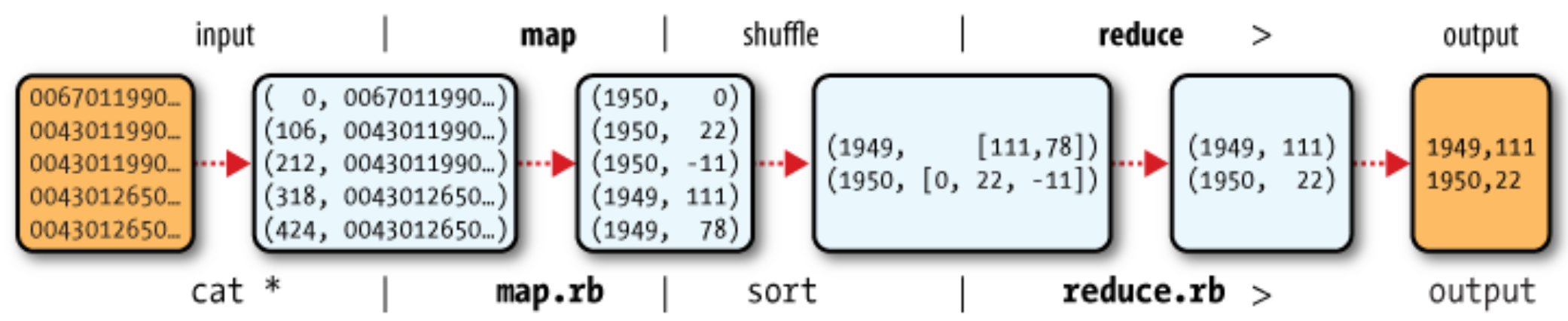
A trival example¶
- Data excerpt
0067011990999991950051507004...9999999N9+00001+99999999999...
0043011990999991950051512004...9999999N9+00221+99999999999...
0043011990999991950051518004...9999999N9-00111+99999999999...
0043012650999991949032412004...0500001N9+01111+99999999999...
0043012650999991949032418004...0500001N9+00781+99999999999...
The keys are the line offsets within the file, which we ignore in our map function.
These lines are presented to the map function as the key-value pairs:
(0, 0067011990999991950051507004...9999999N9+00001+99999999999...)
(106, 0043011990999991950051512004...9999999N9+00221+99999999999...)
(212, 0043011990999991950051518004...9999999N9-00111+99999999999...)
(318, 0043012650999991949032412004...0500001N9+01111+99999999999...)
(424, 0043012650999991949032418004...0500001N9+00781+99999999999...)
The complete case: find the maxmum value of temperatures¶
Input Data: Raw data with temperatures records
Mapper: pull out the year and the air temperature.
(1950, 0)
(1950, 22)
(1950, -11)
(1949, 111)
(1949, 78)
...
- Group and Sort: Sorts and groups the key-value pairs by key.
(1949, [111, 78])
(1950, [0, 22, −11])
...
- Reducer: iterate through the list and pick up the maximum reading
(1949, 111)
(1950, 22)
...
Map-without-Reduce¶
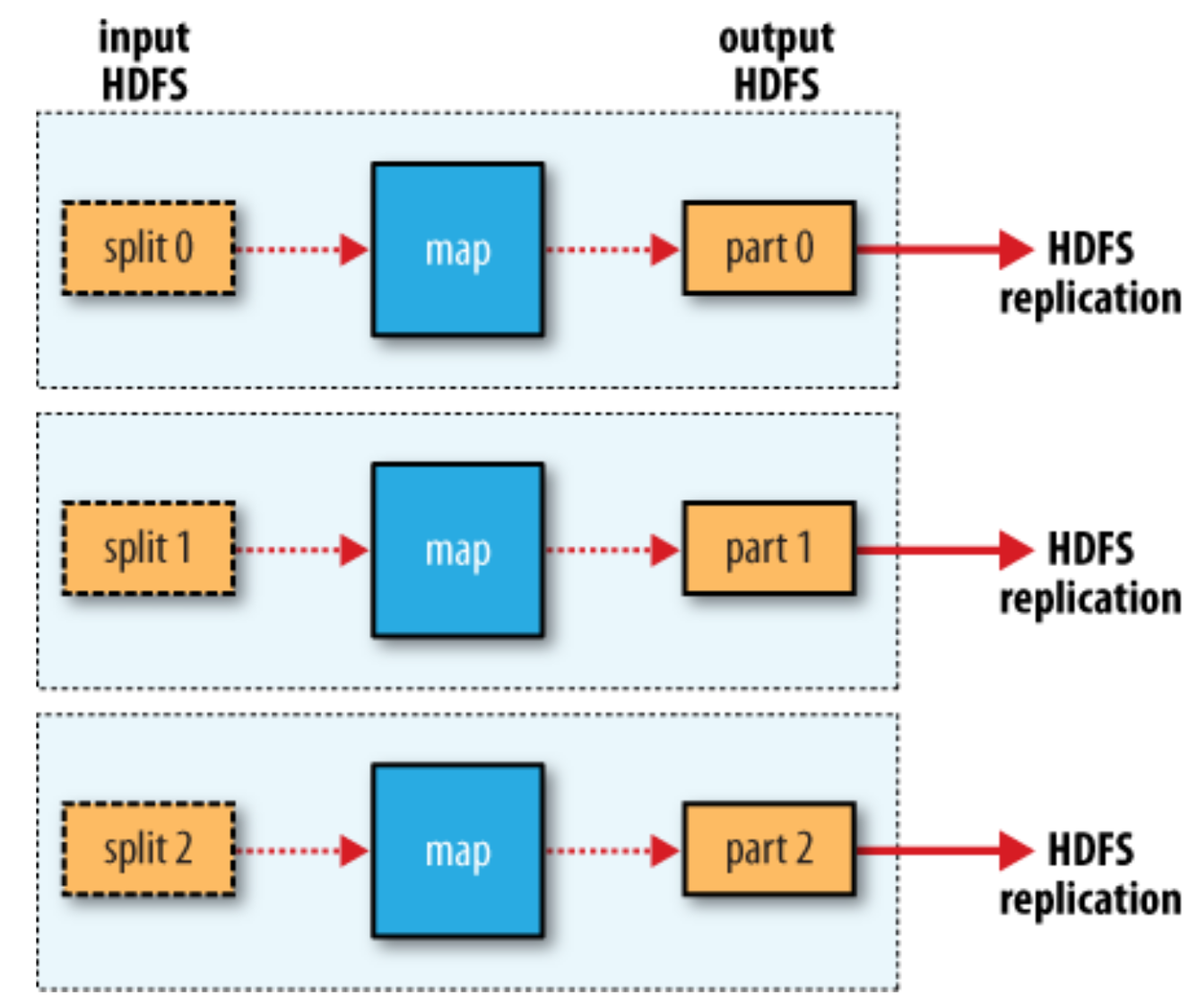
MapReduce data flow with multiple reduce tasks¶
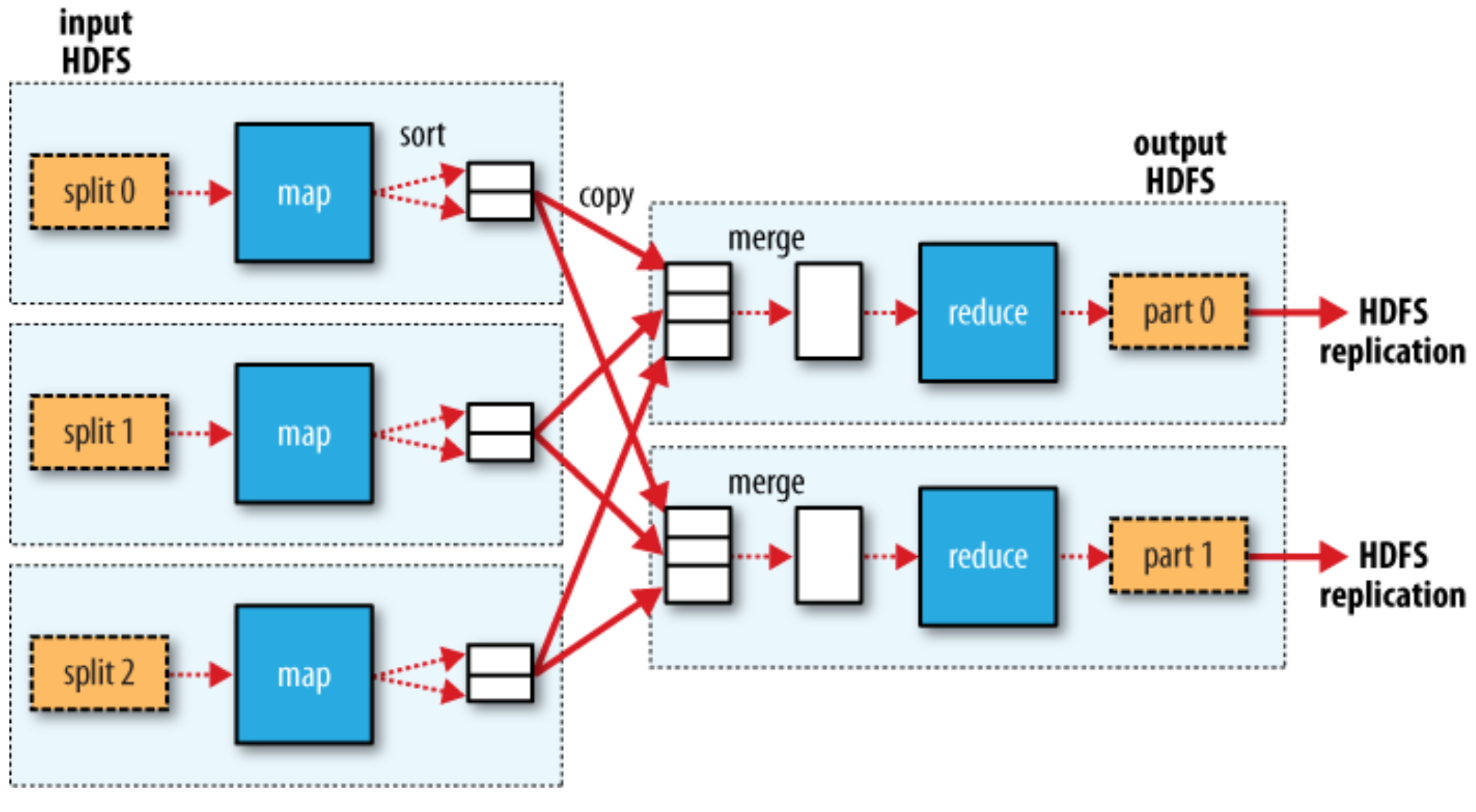
MapReduce data flow with a single reduce task¶
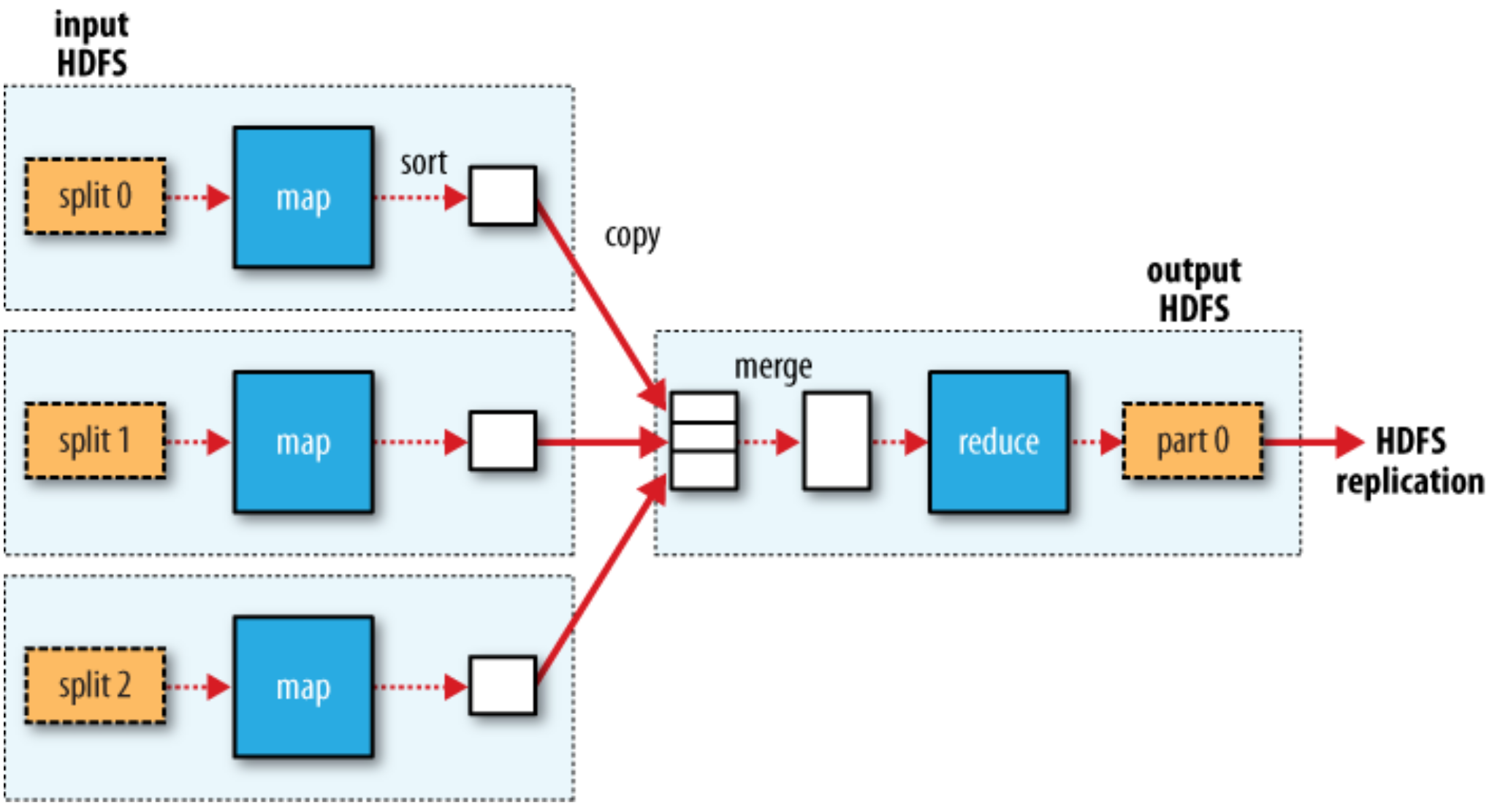
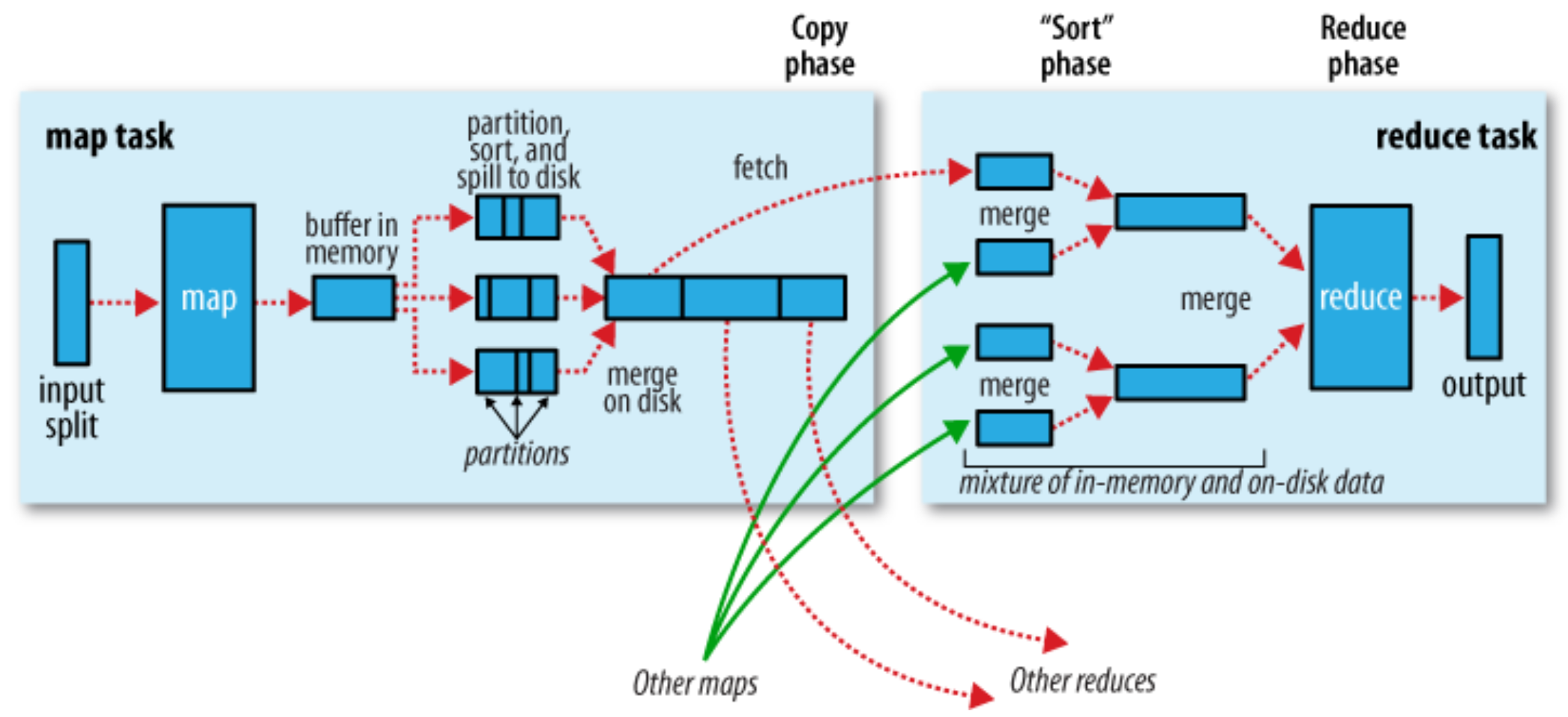
The Map Side¶
- Each map task has a circular memory buffer that it writes the output to.
- When the contents of the buffer reaches a certain threshold size, a background thread will start to spill the contents to disk.
- Before it writes to disk, the thread first divides the data into partitions corresponding to the reducers that they will ultimately be sent to.
- Within each partition, the background thread performs an in-memory sort by key, and if there is a combiner function, it is run on the output of the sort.
The Reduce Side¶
- The map output file is sitting on the local disk of the working machine that ran the map task. (This makes Hadoop slow!)
- The reduce task starts copying their outputs as soon as each map task completes. This is known as the copy phase of the reduce task.
- As the copies accumulate on disk, a background thread merges them into larger, sorted files.
- When all the map outputs have been copied, the reduce task moves into the sort phase.
- During the reduce phase, the reduce function is invoked for each key in the sorted output. The output of this phase is written directly to the output filesystem.
Simulate the whole MapReduce with a Linux pipeline¶
You could test your MapReduce locally with Linux
It simulates a single-map-and-single-reduce task.
cat sample_input.txt | mapper.py | sort | reducer.py
- If your program fails here, it will not work on Hadoop either.