Introduction to Distributed Computing¶
Feng Li¶
Central University of Finance and Economics¶
feng.li@cufe.edu.cn¶
Course home page: https://feng.li/distcomp¶
Why Distributed Systems¶
Moore’s law suited us well for the past decades.
But building bigger and bigger single servers (like IBM supercomputer) is no longer necessarily the best solution to large-scale problems in industry.
An alternative that has gained popularity is to tie together many low-end/commodity machines together as a single functional distributed system.
Distributed Computing is Everywhere¶

The performance of distributed systems¶
A high-end machine with four I/O channels each having a throughput of 100 MB/sec will require three hours to read a 4 TB data set!
With a distributed system, this same data set will be divided into smaller (typically 64 MB) blocks that are spread among many machines in the cluster via the Distributed File System.
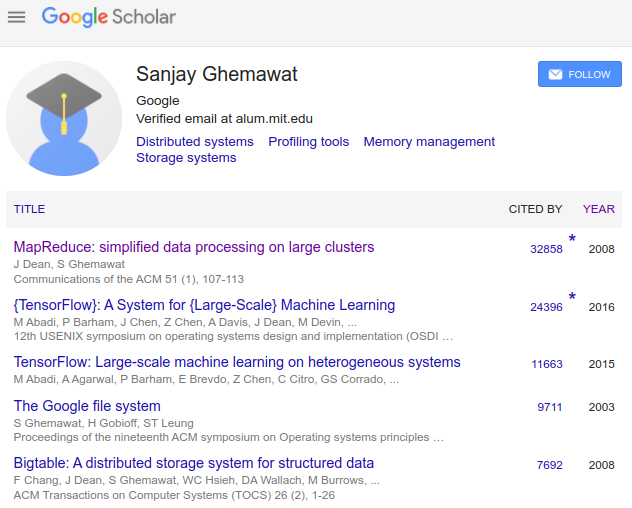
Google's seminal paper for distributed computing¶
The move-code-to-data philosophy¶
The traditional supercomputer requires repeat transmissions of data between clients and servers. This works fine for computationally intensive work, but for data-intensive processing, the size of data becomes too large to be moved around easily.
A distributed systems focuses on moving code to data.
The clients send only the programs to be executed, and these programs are usually small.
More importantly, data are broken up and distributed across the cluster, and as much as possible, computation on a piece of data takes place on the same machine where that piece of data resides.
The whole process is known as MapReduce.
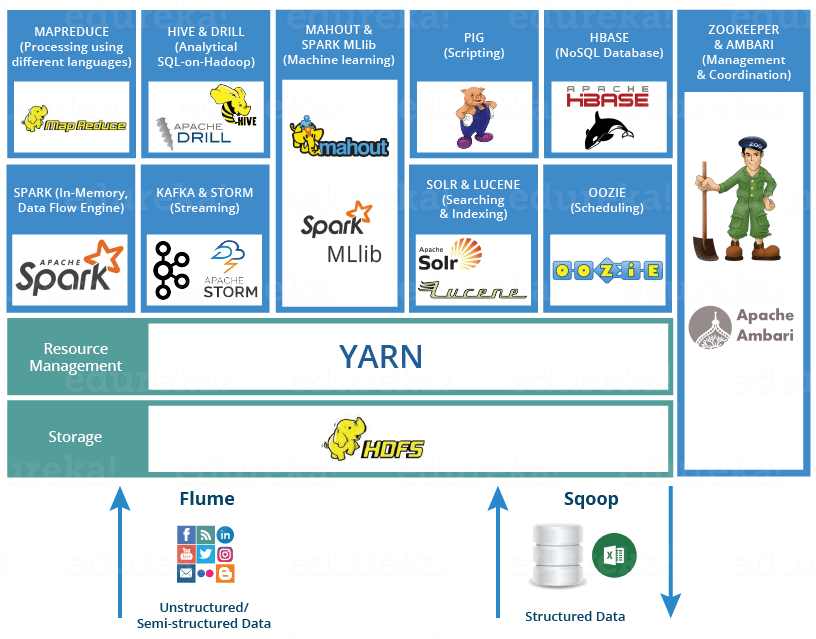
The ecosystem for distributed computing¶
Google's First Distributed Computer¶
