Introduction to forecasting computation¶
Feng Li¶
Guanghua School of Management¶
Peking University¶
feng.li@gsm.pku.edu.cn¶
Course home page: https://feng.li/bdcf¶
Speed up computations with many CPUs and GPUs¶
GPU parallel computing and distributed computing both focus on speeding up computations, but they do so in different ways and are suited for different types of problems.
GPU parallel computing uses a single machine with one or more GPUs (Graphics Processing Units) to perform many calculations simultaneously. GPUs have thousands of cores that can process tasks in parallel, making them highly efficient for tasks like matrix operations and deep learning.
Distributed Computing uses multiple machines (nodes or servers) connected over a network to divide and execute tasks in parallel. It can be structured as clusters, grids, or cloud-based frameworks, using frameworks like Apache Spark.
Comparison Table¶
| Feature | GPU Parallel Computing | Distributed Computing |
|---|---|---|
| Scope | Single machine, multiple cores | Multiple machines, multiple nodes |
| Hardware | GPUs (thousands of cores) | CPUs/GPUs in separate servers |
| Data Size | Limited by GPU memory (VRAM) | Can scale to petabytes of data |
| Computation Type | SIMD (Single Instruction, Multiple Data) | MIMD (Multiple Instructions, Multiple Data) |
| Best Use Cases | Deep learning, HPC, scientific computing | Big data analytics, large-scale web applications |
| Communication Overhead | Minimal (within one machine) | High (network-based communication) |
When to Use What?¶
- Use GPU parallel computing if your task involves massive numerical computations that fit within a single machine (e.g., deep learning, AI training).
- Use distributed computing if you need to process extremely large datasets across multiple machines (e.g., big data analytics with Spark).
The move-code-to-data philosophy¶
The traditional supercomputer requires repeat transmissions of data between clients and servers. This works fine for computationally intensive work, but for data-intensive processing, the size of data becomes too large to be moved around easily.
A distributed systems focuses on moving code to data.
The clients send only the programs to be executed, and these programs are usually small.
More importantly, data are broken up and distributed across the cluster, and as much as possible, computation on a piece of data takes place on the same machine where that piece of data resides.
The whole process is known as MapReduce.

What do we have with Spark?¶

What do we ( statisticians ) miss with distributed platforms?¶
Interpretable statistical models such as GLM and Time Series Forecasting Models.
Efficient Bayesian inference tools such as MCMC, Gibbs and Variational Inference.
Distributed statistical visualization tools like
ggplot2,seabornandplotly...
Why is it difficult to develop statistical models on distributed systems?¶
-- Especially for statisticians
No unified solutions to deploy conventional statistical methods to distributed computing platform.
Steep learning curve for using distributed computing.
Could not balance between estimator efficiency and communication cost.
Unrealistic models assumptions, e.g. requiring data randomly distributed.
Spark APIs for statisticians to develop distributed models¶
UDFs for DataFrames-based API¶
User-Defined Functions (UDFs) are a feature of Spark that allows users to define their own functions when the system's built-in functions are not enough to perform the desired task.
The API is available in Spark (>= 2.3).
It runs with PySpark (requiring Apache
Arrow) and Scala.
Real projects on Spark¶
Code available at https://github.com/feng-li/dstats
DLSA: Least squares approximation for a distributed system¶
in Journal of Computational and Graphical Statistics, 2021 (with Xuening Zhu & Hansheng Wang) https://doi.org/10.1080/10618600.2021.1923517
We estimate the parameter $\theta$ on each worker separately by using local data on distributed workers. This can be done efficiently by using standard statistical estimation methods (e.g., maximum likelihood estimation).
Each worker passes the local estimator of $\theta$ and its asymptotic covariance estimate to the master.
A weighted least squares-type objective function can be constructed. This can be viewed as a local quadratic approximation of the global log-likelihood functions.
Efficiency and cost-effectiveness¶
A standard industrial-level architecture Spark-on-YARN cluster on the Alibaba cloud server consists of one master node and two worker nodes. Each node contains 64 virtual cores, 64 GB of RAM and two 80 GB SSD local hard drives. (cost 300 RMB per day}.
We find that $26.2$ minutes are needed for DLSA.
The traditional MLE takes more that $15$ hours and obtains an inferior result (cost 187 RMB).
That means we have saved 97% computational power. (cost only 6 RMB).
Distributed quantile regression by pilot sampling and one-step updating¶
in Journal of Business and Economic Statistics, 2021 (with Rui Pan, Tunan Ren, Baishan Guo, Guodong Li & Hansheng Wang) https://doi.org/10.1080/07350015.2021.1961789
We conduct a random sampling of size $n$ from the distributed system, where $n$ is much smaller than the whole sample size $N$.
Thereafter, a standard quantile regression estimator can be obtained on the master, which is referred to as the pilot estimator.
To further enhance the statistical efficiency, we propose a one-step Newton-Raphson type algorithm to upgrade the pilot estimator.
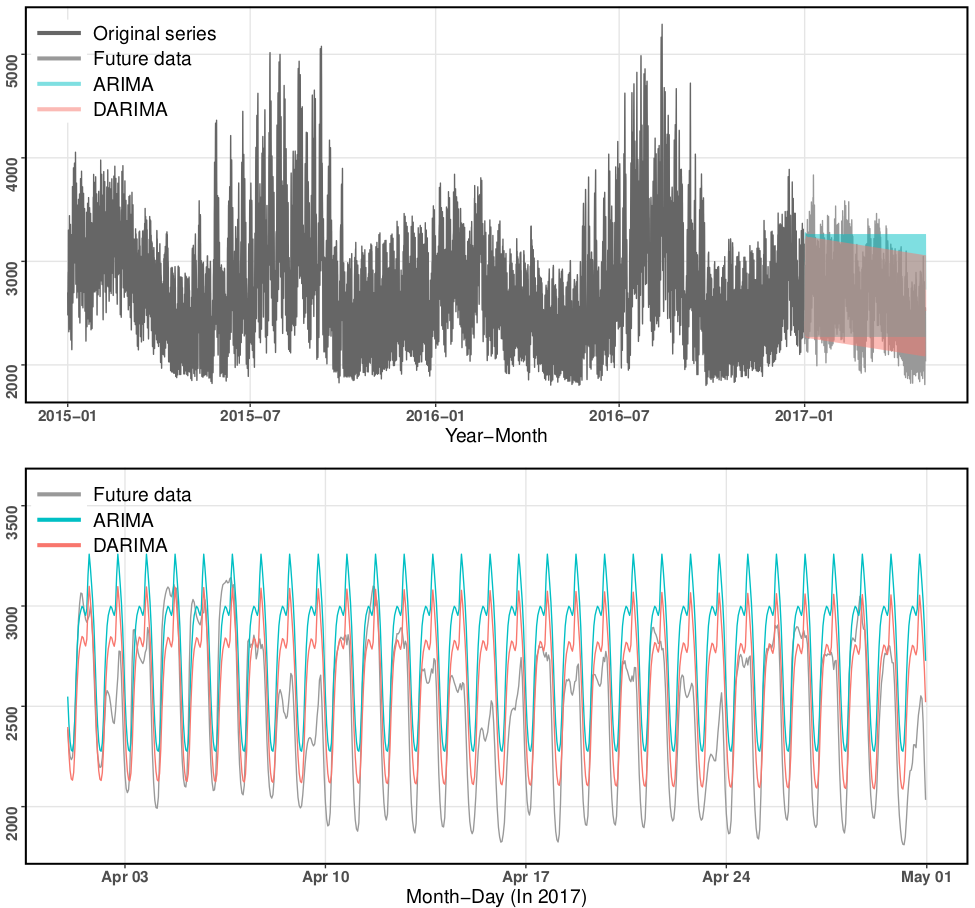
Distributed ARIMA models for ultra-long time series¶
in International Journal of Forecasting, 2023 (with Xiaoqian Wang, Yanfei Kang and Rob J Hyndman)
We develop a novel distributed forecasting framework to tackle challenges associated with forecasting ultra-long time series.
The proposed model combination approach facilitates distributed time series forecasting by combining the local estimators of time series models delivered from worker nodes and minimizing a global loss function.
In this way, instead of unrealistically assuming the data generating process (DGP) of an ultra-long time series stays invariant, we make assumptions only on the DGP of subseries spanning shorter time periods.
Take home message¶
Distributed modeling, computing and visualization are the future of forecasting.
Spark is not the only software for distributed statistical computing,
But is the easiest one.